Cours 6 - Détection de l’encodage d’URL
N.B. Les explications de chaque commande ou de chaque bloc de codes sont données dans les commentaires.
Récapitulatif des trois dernières séances
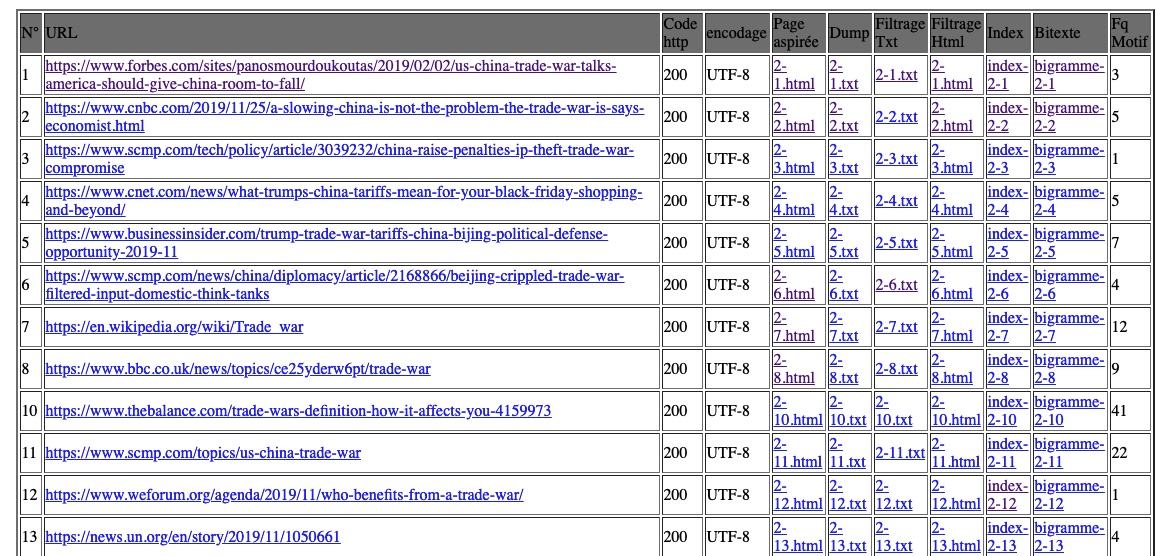
Nous avons établi d’abord des tables de base contenant des URLs à l’aide de deux boucles for, dont l’une pour parcourir tous nos fichiers d’URLs et construire une table pour chaque fichier, soit chaque langue et la deuxième servant à lire les URLs et les écrire dans nos tables ligne à ligne. Nous avons appris que le shell utilise des variables d’environnement dont l’on peut faire apparaître le contenu avec le signe dollar “$”. En utilisant ce signe, nous pouvons stocker et réutiliser le numéro de ligne et le contenu correspondant.
Ayant pour but d’aspirer le contenu de page web et d’en faire des analyses textuelles, nous avons utilisé les commandes curl et lynx. Deux nouvelles colonnes ont été rajoutées pour enregistrer les liens locaux de fichier html et txt dirigés vers le contenu sans format et celui de texte brut de page web.
Ce processus n’est pas automatique à cause des problèmes d’URLs ou de l’encodage. Pour pallier ces problèmes, nous avons détecté si le code de réponse est 200 qui veut dire requête réussie et si l’encodage est UTF-8. Les traitements ultérieurs dépendent des résultats de ces vérifications. Ces deux informations ont également été rajoutées dans nos tables.
Problèmes rencontrés
Nous n’avons pas pris conscience de l’influence d’espace dans le script bash jusqu’au moment de l’apparition des erreurs suivantes :
[200: command not found # ou [405: command not found
[200==200]: command not found
La première erreur provient de
if [ $coderetour == 200 ]
Nous avons utilisé les crochets simples et mis des espaces ente $coderetour et 200.
La deuxième erreur est à cause de
if [$coderetour==200]
qui n’obéit pas à la syntaxe du bash dans laquelle la condition est toujours entourée d’un espace après le crochet d’ouverture et avant le crochet de fermeture.
Nous avons aussi essayé de comprendre la différence entre les crochets simples et doubles.
Les conditions à crochets doubles permettent tout ce qu’offrent les conditions à crochets simples. En outre, elles acceptent l’usage du wildcard comme en bash ainsi que des expressions régulières.
Voici la dernière version de script accompagnée des explications de certaines commandes bash dans les commentaires.
# !/bin/bash
# on commence par effacer l'éventuel contenu de ficher que l'on doit réécrire
echo "" > "$2/tableau.html";
# ou
# rm -f "$2/tableau.html" ;
# on récupère les 2 arguments que l'on a passés au programme
# le premier : chemin vers le dossier contenant les fichiers d'URL
# le second : chemin vers le dossier devant contenir le fichier HTML final
echo "les urls sont dans : $1";
echo "chemin de stockage : $2";
# 1. définir le type <html>
echo "<html><head><meta charset=\"UTF-8\"><title>Tableaux</title></head><body>" >> "$2/tableau.html";
# 2. générer un tableau par fichier d'URL
numeroTable=1;
# pour tous les fichiers dans le répertoire 1
# for fichier in $1/*
for fichier in $(ls $1)
# on exécute les commandes suivantes
do
# compteur destiné à compter les URLs pour chaque fichier d'URL
compteur=1;
echo "$1/$fichier";
echo "<table border=\"2\" align=\"center\" width=\"80%\">" >> "$2/tableau.html";
# lecture ligne à ligne des URLs
for ligne in $(cat "$1/$fichier")
do
# curl : un outil de transfert de data de ou vers un serveur
# options :
# -o output file
# -s silent, use -S, --show-error in addition to this option to disable progress meter but still show error messages
# -I head, fetch the headers only
# -L location, if the server reports that the requested page has moved to a different location, this option will make curl redo the request on the new place.
# -w write-out, Make curl display information on stdout after a completed transfer
coderetour=$(curl -SIL -o tmp.txt -w %{http_code} $ligne);
# si coderetour égal à 200
if [[ $coderetour == 200 ]]
then
# normaliser la case, tout est en majuscule, comme UTF-8
# supprimer eventuellement la fin de ligne
encodage=$(curl -sIL -o toto -w %{content_type} $ligne|cut -f2 -d"="|tr '[a-z]' '[A-Z]'|tr -d '\n');
# quand on ouvre un fichier, le reprtoire sera le sien
# pour relier $numeroTable et $compteur, '-' marche mais pas '_'?????
curl -L -o "../PAGES-ASPIREES/$numeroTable-$compteur.html" "$ligne";
if [[ $encodage == 'UTF-8' ]]
then
lynx -dump -nolist -assume-charset=$encodage - display-charset=$encodage "../PAGE_ASPIREES/$numeroTable-$compteur.html" > ../DUMP-TEXT/$numeroTable-$compteur.txt;
echo "<tr><td>$compteur</td><td><a href=\"$ligne\" target=\"_blank\">$ligne</a></td><td>Code_http:$coderetour</td><td>Encodage:$encodage</td><td><a href=\"../PAGE-ASPIREES/$numeroTable-$compteur.html\">$numeroTable-$compteur.html</a></td><td><a href=\"../DUMP-TEXT/$numeroTable-$compteur.txt\">$numeroTable-$compteur.txt</a></td></tr>" >> "$2/tableau.html";
else
# comment savoir si la valeur est connu de iconv
# extraction de l'encodage avec egrep dans la page aspiree
# lynx dump avec l'encodage trouve
# convertir le dump en utf8 avec iconv
echo "<tr><td>$compteur</td><td><a href=\"$ligne\" target=\"_blank\">$ligne</a></td><td>Code_http:$coderetour</td><td>Encodage:$encodage</td><td><a href=\"../PAGE_ASPIREES/$numeroTable-$compteur.html\">"$numeroTable-$compteur.html"</a></td><td>-</td></tr>" >> "$2/tableau.html";
fi
else
echo "<tr><td>$compteur</td><td><a href=\"$ligne\" target=\"_blank\">$ligne</a></td><td>Code_http:$coderetour</td><td>-</td><td>-</td><td>-</td></tr>" >> "$2/tableau.html";
fi
compteur=$((compteur+1));
done
echo "</table><br />" >> "$2/tableau.html";
# cat $fichier >> "$2/tableau.html"
numeroTable=$((numeroTable+1));
done
echo "</body></html>" >> "$2/tableau.html";